 java.lang.String
java.lang.String
|
JavaTM Platform Standard Ed. 6 |
|||||||||
| …ѕ“їЄцја ѕ¬“їЄцја | њтЉ№ ќёњтЉ№ | |||||||||
| ’™“™£Ї «ґћ„ | „÷ґќ | єє‘мЈљЈ® | ЈљЈ® | ѕкѕЄ–≈ѕҐ£Ї „÷ґќ | єє‘мЈљЈ® | ЈљЈ® | |||||||||
java.lang.Object
public final class String
String јаіъ±н„÷ЈыіЃ°£Java ≥ћ–т÷–µƒЋщ”–„÷ЈыіЃ„÷√ж÷µ£®»з "abc" £©ґЉ„чќ™іЋјаµƒ µјэ µѕ÷°£
„÷ЈыіЃ «≥£Ѕњ£їЋь√«µƒ÷µ‘Џііљ®÷ЃЇу≤їƒ№ЄьЄƒ°£„÷ЈыіЃїЇ≥е«ш÷І≥÷њ…±дµƒ„÷ЈыіЃ°£“тќ™ String ґ‘ѕу «≤їњ…±дµƒ£ђЋщ“‘њ…“‘є≤ѕн°£јэ»з£Ї
String str = "abc";
µ»–І”Џ£Ї
char data[] = {'a', 'b', 'c'};
String str = new String(data);
ѕ¬√жЄш≥цЅЋ“ї–©»зЇќ є”√„÷ЈыіЃµƒЄьґа Њјэ£Ї
System.out.println("abc");
String cde = "cde";
System.out.println("abc" + cde);
String c = "abc".substring(2,3);
String d = cde.substring(1, 2);
String ја∞ьј®µƒЈљЈ®њ…”√”ЏЉм≤й–тЅ–µƒµ•Єц„÷Јы°Ґ±»љѕ„÷ЈыіЃ°ҐЋ—Ћч„÷ЈыіЃ°Ґћб»°„”„÷ЈыіЃ°Ґііљ®„÷ЈыіЃЄ±±Њ≤ҐљЂЋщ”–„÷Јы»Ђ≤њ„™їїќ™іу–іїт–°–і°£іу–°–і”≥…дїщ”Џ Character ја÷Єґ®µƒ Unicode ±к„Љ∞ж°£
Java ”п—‘ћбє©ґ‘„÷ЈыіЃіЃЅ™ЈыЇ≈£®"+"£©“‘Љ∞љЂ∆дЋыґ‘ѕу„™їїќ™„÷ЈыіЃµƒћЎ в÷І≥÷°£„÷ЈыіЃіЃЅ™ «Ќ®єэ StringBuilder£®їт StringBuffer£©јаЉ∞∆д append ЈљЈ® µѕ÷µƒ°£„÷ЈыіЃ„™її «Ќ®єэ toString ЈљЈ® µѕ÷µƒ£ђЄ√ЈљЈ®”… Object јаґ®“е£ђ≤Ґњ…±ї Java ÷–µƒЋщ”–јаЉћ≥–°£”–єЎ„÷ЈыіЃіЃЅ™ЇЌ„™їїµƒЄьґа–≈ѕҐ£ђ«л≤ќ‘ƒ Gosling°ҐJoy ЇЌ Steele Їѕ÷шµƒ The Java Language Specification°£
≥эЈ«Ѕн––Ћµ√ч£ђЈс‘тљЂ null ≤ќ эіЂµЁЄшіЋја÷–µƒєє‘мЈљЈ®їтЈљЈ®љЂ≈„≥ц NullPointerException°£
String ±н Њ“їЄц UTF-16 Єс љµƒ„÷ЈыіЃ£ђ∆д÷–µƒ‘ц≤є„÷Јы ”…іъјнѕоґ‘ ±н Њ£®”–єЎѕкѕЄ–≈ѕҐ£ђ«л≤ќ‘ƒ Character ја÷–µƒ Unicode „÷Јы±н Њ–ќ љ£©°£Ћч“э÷µ «÷Є char іъ¬лµ•‘™£ђ“тіЋ‘ц≤є„÷Јы‘Џ String ÷–’Љ”√ЅљЄцќї÷√°£
String јаћбє©і¶јн Unicode іъ¬лµг£®Љі„÷Јы£©ЇЌ Unicode іъ¬лµ•‘™£®Љі char ÷µ£©µƒЈљЈ®°£
Object.toString(),
StringBuffer,
StringBuilder,
Charset,
–тЅ–їѓ±нЄс| „÷ґќ’™“™ | |
|---|---|
static Comparator<String> |
CASE_INSENSITIVE_ORDER
“їЄцґ‘ String ґ‘ѕуљш––≈≈–тµƒ Comparator£ђ„ч”√”л compareToIgnoreCase ѕаЌђ°£ |
| єє‘мЈљЈ®’™“™ | |
|---|---|
String()
≥х Љїѓ“їЄц–¬ііљ®µƒ String ґ‘ѕу£ђ є∆д±н Њ“їЄцњ’„÷Јы–тЅ–°£ |
|
String(byte[] bytes)
Ќ®єэ є”√∆љћ®µƒƒђ»ѕ„÷ЈыЉѓљв¬л÷Єґ®µƒ byte э„й£ђєє‘м“їЄц–¬µƒ String°£ |
|
String(byte[] bytes,
Charset charset)
Ќ®єэ є”√÷Єґ®µƒ charset љв¬л÷Єґ®µƒ byte э„й£ђєє‘м“їЄц–¬µƒ String°£ |
|
String(byte[] ascii,
int hibyte)
“—єэ ±°£ Є√ЈљЈ®ќёЈ®љЂ„÷љЏ’э»ЈµЎ„™їїќ™„÷Јы°£і” JDK 1.1 њ™ Љ£ђЌк≥…Є√„™їїµƒ „—°ЈљЈ® « є”√іш”– Charset°Ґ„÷ЈыЉѓ√ы≥∆£ђїт є”√∆љћ®ƒђ»ѕ„÷ЈыЉѓµƒ String єє‘мЈљЈ®°£ |
|
String(byte[] bytes,
int offset,
int length)
Ќ®єэ є”√∆љћ®µƒƒђ»ѕ„÷ЈыЉѓљв¬л÷Єґ®µƒ byte „” э„й£ђєє‘м“їЄц–¬µƒ String°£ |
|
String(byte[] bytes,
int offset,
int length,
Charset charset)
Ќ®єэ є”√÷Єґ®µƒ charset љв¬л÷Єґ®µƒ byte „” э„й£ђєє‘м“їЄц–¬µƒ String°£ |
|
String(byte[] ascii,
int hibyte,
int offset,
int count)
“—єэ ±°£ Є√ЈљЈ®ќёЈ®љЂ„÷љЏ’э»ЈµЎ„™їїќ™„÷Јы°£і” JDK 1.1 њ™ Љ£ђЌк≥…Є√„™їїµƒ „—°ЈљЈ® « є”√іш”– Charset°Ґ„÷ЈыЉѓ√ы≥∆£ђїт є”√∆љћ®ƒђ»ѕ„÷ЈыЉѓµƒ String єє‘мЈљЈ®°£ |
|
String(byte[] bytes,
int offset,
int length,
String charsetName)
Ќ®єэ є”√÷Єґ®µƒ„÷ЈыЉѓљв¬л÷Єґ®µƒ byte „” э„й£ђєє‘м“їЄц–¬µƒ String°£ |
|
String(byte[] bytes,
String charsetName)
Ќ®єэ є”√÷Єґ®µƒ charset љв¬л÷Єґ®µƒ byte э„й£ђєє‘м“їЄц–¬µƒ String°£ |
|
String(char[] value)
Ј÷≈д“їЄц–¬µƒ String£ђ є∆д±н Њ„÷Јы э„й≤ќ э÷–µ±«∞∞ьЇђµƒ„÷Јы–тЅ–°£ |
|
String(char[] value,
int offset,
int count)
Ј÷≈д“їЄц–¬µƒ String£ђЋь∞ьЇђ»°„‘„÷Јы э„й≤ќ э“їЄц„” э„йµƒ„÷Јы°£ |
|
String(int[] codePoints,
int offset,
int count)
Ј÷≈д“їЄц–¬µƒ String£ђЋь∞ьЇђ Unicode іъ¬лµг э„й≤ќ э“їЄц„” э„йµƒ„÷Јы°£ |
|
String(String original)
≥х Љїѓ“їЄц–¬ііљ®µƒ String ґ‘ѕу£ђ є∆д±н Њ“їЄц”л≤ќ эѕаЌђµƒ„÷Јы–тЅ–£їїїЊдї∞Ћµ£ђ–¬ііљ®µƒ„÷ЈыіЃ «Є√≤ќ э„÷ЈыіЃµƒЄ±±Њ°£ |
|
String(StringBuffer buffer)
Ј÷≈д“їЄц–¬µƒ„÷ЈыіЃ£ђЋь∞ьЇђ„÷ЈыіЃїЇ≥е«ш≤ќ э÷–µ±«∞∞ьЇђµƒ„÷Јы–тЅ–°£ |
|
String(StringBuilder builder)
Ј÷≈д“їЄц–¬µƒ„÷ЈыіЃ£ђЋь∞ьЇђ„÷ЈыіЃ…ъ≥…∆ч≤ќ э÷–µ±«∞∞ьЇђµƒ„÷Јы–тЅ–°£ |
|
| ЈљЈ®’™“™ | |
|---|---|
char |
charAt(int index)
ЈµїЎ÷Єґ®Ћч“эі¶µƒ char ÷µ°£ |
int |
codePointAt(int index)
ЈµїЎ÷Єґ®Ћч“эі¶µƒ„÷Јы£®Unicode іъ¬лµг£©°£ |
int |
codePointBefore(int index)
ЈµїЎ÷Єґ®Ћч“э÷Ѓ«∞µƒ„÷Јы£®Unicode іъ¬лµг£©°£ |
int |
codePointCount(int beginIndex,
int endIndex)
ЈµїЎіЋ String µƒ÷Єґ®ќƒ±ЊЈґќІ÷–µƒ Unicode іъ¬лµг э°£ |
int |
compareTo(String anotherString)
∞і„÷µдЋ≥–т±»љѕЅљЄц„÷ЈыіЃ°£ |
int |
compareToIgnoreCase(String str)
∞і„÷µдЋ≥–т±»љѕЅљЄц„÷ЈыіЃ£ђ≤їњЉ¬«іу–°–і°£ |
String |
concat(String str)
љЂ÷Єґ®„÷ЈыіЃЅђљ”µљіЋ„÷ЈыіЃµƒљбќ≤°£ |
boolean |
contains(CharSequence s)
µ±«“љцµ±іЋ„÷ЈыіЃ∞ьЇђ÷Єґ®µƒ char ÷µ–тЅ– ±£ђЈµїЎ true°£ |
boolean |
contentEquals(CharSequence cs)
љЂіЋ„÷ЈыіЃ”л÷Єґ®µƒ CharSequence ±»љѕ°£ |
boolean |
contentEquals(StringBuffer sb)
љЂіЋ„÷ЈыіЃ”л÷Єґ®µƒ StringBuffer ±»љѕ°£ |
static String |
copyValueOf(char[] data)
ЈµїЎ÷Єґ® э„й÷–±н ЊЄ√„÷Јы–тЅ–µƒ String°£ |
static String |
copyValueOf(char[] data,
int offset,
int count)
ЈµїЎ÷Єґ® э„й÷–±н ЊЄ√„÷Јы–тЅ–µƒ String°£ |
boolean |
endsWith(String suffix)
≤в ‘іЋ„÷ЈыіЃ «Јс“‘÷Єґ®µƒЇу„Їљб ш°£ |
boolean |
equals(Object anObject)
љЂіЋ„÷ЈыіЃ”л÷Єґ®µƒґ‘ѕу±»љѕ°£ |
boolean |
equalsIgnoreCase(String anotherString)
љЂіЋ String ”лЅн“їЄц String ±»љѕ£ђ≤їњЉ¬«іу–°–і°£ |
static String |
format(Locale l,
String format,
Object... args)
є”√÷Єґ®µƒ”п—‘їЈЊ≥°ҐЄс љ„÷ЈыіЃЇЌ≤ќ эЈµїЎ“їЄцЄс љїѓ„÷ЈыіЃ°£ |
static String |
format(String format,
Object... args)
є”√÷Єґ®µƒЄс љ„÷ЈыіЃЇЌ≤ќ эЈµїЎ“їЄцЄс љїѓ„÷ЈыіЃ°£ |
byte[] |
getBytes()
є”√∆љћ®µƒƒђ»ѕ„÷ЈыЉѓљЂіЋ String ±а¬лќ™ byte –тЅ–£ђ≤ҐљЂљбєыіжіҐµљ“їЄц–¬µƒ byte э„й÷–°£ |
byte[] |
getBytes(Charset charset)
є”√Єшґ®µƒ charset љЂіЋ String ±а¬лµљ byte –тЅ–£ђ≤ҐљЂљбєыіжіҐµљ–¬µƒ byte э„й°£ |
void |
getBytes(int srcBegin,
int srcEnd,
byte[] dst,
int dstBegin)
“—єэ ±°£ Є√ЈљЈ®ќёЈ®љЂ„÷Јы’э»Ј„™їїќ™„÷љЏ°£і” JDK 1.1 ∆р£ђЌк≥…Є√„™їїµƒ „—°ЈљЈ® «Ќ®єэ getBytes() ЈљЈ®£ђЄ√ЈљЈ® є”√∆љћ®µƒƒђ»ѕ„÷ЈыЉѓ°£ |
byte[] |
getBytes(String charsetName)
є”√÷Єґ®µƒ„÷ЈыЉѓљЂіЋ String ±а¬лќ™ byte –тЅ–£ђ≤ҐљЂљбєыіжіҐµљ“їЄц–¬µƒ byte э„й÷–°£ |
void |
getChars(int srcBegin,
int srcEnd,
char[] dst,
int dstBegin)
љЂ„÷Јыі”іЋ„÷ЈыіЃЄі÷∆µљƒњ±к„÷Јы э„й°£ |
int |
hashCode()
ЈµїЎіЋ„÷ЈыіЃµƒєюѕ£¬л°£ |
int |
indexOf(int ch)
ЈµїЎ÷Єґ®„÷Јы‘ЏіЋ„÷ЈыіЃ÷–µЏ“їіќ≥цѕ÷і¶µƒЋч“э°£ |
int |
indexOf(int ch,
int fromIndex)
ЈµїЎ‘ЏіЋ„÷ЈыіЃ÷–µЏ“їіќ≥цѕ÷÷Єґ®„÷Јыі¶µƒЋч“э£ђі”÷Єґ®µƒЋч“эњ™ ЉЋ—Ћч°£ |
int |
indexOf(String str)
ЈµїЎ÷Єґ®„”„÷ЈыіЃ‘ЏіЋ„÷ЈыіЃ÷–µЏ“їіќ≥цѕ÷і¶µƒЋч“э°£ |
int |
indexOf(String str,
int fromIndex)
ЈµїЎ÷Єґ®„”„÷ЈыіЃ‘ЏіЋ„÷ЈыіЃ÷–µЏ“їіќ≥цѕ÷і¶µƒЋч“э£ђі”÷Єґ®µƒЋч“эњ™ Љ°£ |
String |
intern()
ЈµїЎ„÷ЈыіЃґ‘ѕуµƒєжЈґїѓ±н Њ–ќ љ°£ |
boolean |
isEmpty()
µ±«“љцµ± length() ќ™ 0 ±ЈµїЎ true°£ |
int |
lastIndexOf(int ch)
ЈµїЎ÷Єґ®„÷Јы‘ЏіЋ„÷ЈыіЃ÷–„оЇу“їіќ≥цѕ÷і¶µƒЋч“э°£ |
int |
lastIndexOf(int ch,
int fromIndex)
ЈµїЎ÷Єґ®„÷Јы‘ЏіЋ„÷ЈыіЃ÷–„оЇу“їіќ≥цѕ÷і¶µƒЋч“э£ђі”÷Єґ®µƒЋч“эі¶њ™ Љљш––ЈіѕтЋ—Ћч°£ |
int |
lastIndexOf(String str)
ЈµїЎ÷Єґ®„”„÷ЈыіЃ‘ЏіЋ„÷ЈыіЃ÷–„о”“±я≥цѕ÷і¶µƒЋч“э°£ |
int |
lastIndexOf(String str,
int fromIndex)
ЈµїЎ÷Єґ®„”„÷ЈыіЃ‘ЏіЋ„÷ЈыіЃ÷–„оЇу“їіќ≥цѕ÷і¶µƒЋч“э£ђі”÷Єґ®µƒЋч“эњ™ ЉЈіѕтЋ—Ћч°£ |
int |
length()
ЈµїЎіЋ„÷ЈыіЃµƒ≥§ґ»°£ |
boolean |
matches(String regex)
Єж÷™іЋ„÷ЈыіЃ «Јс∆•≈дЄшґ®µƒ’э‘т±ніп љ°£ |
int |
offsetByCodePoints(int index,
int codePointOffset)
ЈµїЎіЋ String ÷–і”Єшґ®µƒ index і¶∆Ђ“∆ codePointOffset Єціъ¬лµгµƒЋч“э°£ |
boolean |
regionMatches(boolean ignoreCase,
int toffset,
String other,
int ooffset,
int len)
≤в ‘ЅљЄц„÷ЈыіЃ«ш”т «Јсѕаµ»°£ |
boolean |
regionMatches(int toffset,
String other,
int ooffset,
int len)
≤в ‘ЅљЄц„÷ЈыіЃ«ш”т «Јсѕаµ»°£ |
String |
replace(char oldChar,
char newChar)
ЈµїЎ“їЄц–¬µƒ„÷ЈыіЃ£ђЋь «Ќ®єэ”√ newChar ћжїїіЋ„÷ЈыіЃ÷–≥цѕ÷µƒЋщ”– oldChar µ√µљµƒ°£ |
String |
replace(CharSequence target,
CharSequence replacement)
є”√÷Єґ®µƒ„÷√ж÷µћжїї–тЅ–ћжїїіЋ„÷ЈыіЃЋщ”–∆•≈д„÷√ж÷µƒњ±к–тЅ–µƒ„”„÷ЈыіЃ°£ |
String |
replaceAll(String regex,
String replacement)
є”√Єшґ®µƒ replacement ћжїїіЋ„÷ЈыіЃЋщ”–∆•≈дЄшґ®µƒ’э‘т±ніп љµƒ„”„÷ЈыіЃ°£ |
String |
replaceFirst(String regex,
String replacement)
є”√Єшґ®µƒ replacement ћжїїіЋ„÷ЈыіЃ∆•≈дЄшґ®µƒ’э‘т±ніп љµƒµЏ“їЄц„”„÷ЈыіЃ°£ |
String[] |
split(String regex)
ЄщЊЁЄшґ®’э‘т±ніп љµƒ∆•≈д≤рЈ÷іЋ„÷ЈыіЃ°£ |
String[] |
split(String regex,
int limit)
ЄщЊЁ∆•≈дЄшґ®µƒ’э‘т±ніп љјі≤рЈ÷іЋ„÷ЈыіЃ°£ |
boolean |
startsWith(String prefix)
≤в ‘іЋ„÷ЈыіЃ «Јс“‘÷Єґ®µƒ«∞„Їњ™ Љ°£ |
boolean |
startsWith(String prefix,
int toffset)
≤в ‘іЋ„÷ЈыіЃі”÷Єґ®Ћч“эњ™ Љµƒ„”„÷ЈыіЃ «Јс“‘÷Єґ®«∞„Їњ™ Љ°£ |
CharSequence |
subSequence(int beginIndex,
int endIndex)
ЈµїЎ“їЄц–¬µƒ„÷Јы–тЅ–£ђЋь «іЋ–тЅ–µƒ“їЄц„”–тЅ–°£ |
String |
substring(int beginIndex)
ЈµїЎ“їЄц–¬µƒ„÷ЈыіЃ£ђЋь «іЋ„÷ЈыіЃµƒ“їЄц„”„÷ЈыіЃ°£ |
String |
substring(int beginIndex,
int endIndex)
ЈµїЎ“їЄц–¬„÷ЈыіЃ£ђЋь «іЋ„÷ЈыіЃµƒ“їЄц„”„÷ЈыіЃ°£ |
char[] |
toCharArray()
љЂіЋ„÷ЈыіЃ„™їїќ™“їЄц–¬µƒ„÷Јы э„й°£ |
String |
toLowerCase()
є”√ƒђ»ѕ”п—‘їЈЊ≥µƒєж‘тљЂіЋ String ÷–µƒЋщ”–„÷ЈыґЉ„™їїќ™–°–і°£ |
String |
toLowerCase(Locale locale)
є”√Єшґ® Locale µƒєж‘тљЂіЋ String ÷–µƒЋщ”–„÷ЈыґЉ„™їїќ™–°–і°£ |
String |
toString()
ЈµїЎіЋґ‘ѕу±Њ…н£®Ћь“—Њ≠ «“їЄц„÷ЈыіЃ£°£©°£ |
String |
toUpperCase()
є”√ƒђ»ѕ”п—‘їЈЊ≥µƒєж‘тљЂіЋ String ÷–µƒЋщ”–„÷ЈыґЉ„™їїќ™іу–і°£ |
String |
toUpperCase(Locale locale)
є”√Єшґ® Locale µƒєж‘тљЂіЋ String ÷–µƒЋщ”–„÷ЈыґЉ„™їїќ™іу–і°£ |
String |
trim()
ЈµїЎ„÷ЈыіЃµƒЄ±±Њ£ђЇц¬‘«∞µЉњ’∞„ЇЌќ≤≤њњ’∞„°£ |
static String |
valueOf(boolean b)
ЈµїЎ boolean ≤ќ эµƒ„÷ЈыіЃ±н Њ–ќ љ°£ |
static String |
valueOf(char c)
ЈµїЎ char ≤ќ эµƒ„÷ЈыіЃ±н Њ–ќ љ°£ |
static String |
valueOf(char[] data)
ЈµїЎ char э„й≤ќ эµƒ„÷ЈыіЃ±н Њ–ќ љ°£ |
static String |
valueOf(char[] data,
int offset,
int count)
ЈµїЎ char э„й≤ќ эµƒћЎґ®„” э„йµƒ„÷ЈыіЃ±н Њ–ќ љ°£ |
static String |
valueOf(double d)
ЈµїЎ double ≤ќ эµƒ„÷ЈыіЃ±н Њ–ќ љ°£ |
static String |
valueOf(float f)
ЈµїЎ float ≤ќ эµƒ„÷ЈыіЃ±н Њ–ќ љ°£ |
static String |
valueOf(int i)
ЈµїЎ int ≤ќ эµƒ„÷ЈыіЃ±н Њ–ќ љ°£ |
static String |
valueOf(long l)
ЈµїЎ long ≤ќ эµƒ„÷ЈыіЃ±н Њ–ќ љ°£ |
static String |
valueOf(Object obj)
ЈµїЎ Object ≤ќ эµƒ„÷ЈыіЃ±н Њ–ќ љ°£ |
| і”ја java.lang.Object Љћ≥–µƒЈљЈ® |
|---|
clone, finalize, getClass, notify, notifyAll, wait, wait, wait |
| „÷ґќѕкѕЄ–≈ѕҐ |
|---|
public static final Comparator<String> CASE_INSENSITIVE_ORDER
String ґ‘ѕуљш––≈≈–тµƒ Comparator£ђ„ч”√”л compareToIgnoreCase ѕаЌђ°£іЋ±»љѕ∆ч «њ…–тЅ–їѓµƒ°£
„Ґ“в£ђComparator ≤ї њЉ¬«”п—‘їЈЊ≥£ђ“тіЋњ…ƒ№µЉ÷¬‘Џƒ≥–©”п—‘їЈЊ≥÷–µƒ≈≈–т–Ієы≤їјнѕл°£java.text ∞ьћбє© Collator Ќк≥…”л”п—‘їЈЊ≥”–єЎµƒ≈≈–т°£
Collator.compare(String, String)| єє‘мЈљЈ®ѕкѕЄ–≈ѕҐ |
|---|
public String()
String ґ‘ѕу£ђ є∆д±н Њ“їЄцњ’„÷Јы–тЅ–°£„Ґ“в£ђ”…”Џ String «≤їњ…±дµƒ£ђЋщ“‘ќё–и є”√іЋєє‘мЈљЈ®°£
public String(String original)
String ґ‘ѕу£ђ є∆д±н Њ“їЄц”л≤ќ эѕаЌђµƒ„÷Јы–тЅ–£їїїЊдї∞Ћµ£ђ–¬ііљ®µƒ„÷ЈыіЃ «Є√≤ќ э„÷ЈыіЃµƒЄ±±Њ°£”…”Џ String «≤їњ…±дµƒ£ђЋщ“‘ќё–и є”√іЋєє‘мЈљЈ®£ђ≥эЈ«–и“™ original µƒѕ‘ љЄ±±Њ°£
original - “їЄц String°£public String(char[] value)
String£ђ є∆д±н Њ„÷Јы э„й≤ќ э÷–µ±«∞∞ьЇђµƒ„÷Јы–тЅ–°£Є√„÷Јы э„йµƒƒЏ»Ё“—±їЄі÷∆£їЇу–шґ‘„÷Јы э„йµƒ–ёЄƒ≤їїб”∞ѕм–¬ііљ®µƒ„÷ЈыіЃ°£
value - „÷ЈыіЃµƒ≥х Љ÷µ
public String(char[] value,
int offset,
int count)
String£ђЋь∞ьЇђ»°„‘„÷Јы э„й≤ќ э“їЄц„” э„йµƒ„÷Јы°£offset ≤ќ э «„” э„йµЏ“їЄц„÷ЈыµƒЋч“э£ђcount ≤ќ э÷Єґ®„” э„йµƒ≥§ґ»°£Є√„” э„йµƒƒЏ»Ё“—±їЄі÷∆£їЇу–шґ‘„÷Јы э„йµƒ–ёЄƒ≤їїб”∞ѕм–¬ііљ®µƒ„÷ЈыіЃ°£
value - „чќ™„÷Јы‘іµƒ э„й°£offset - ≥х Љ∆Ђ“∆Ѕњ°£count - ≥§ґ»°£
IndexOutOfBoundsException - »зєы offset ЇЌ count ≤ќ эЋч“э„÷Јы≥ђ≥ц value э„йµƒЈґќІ°£
public String(int[] codePoints,
int offset,
int count)
String£ђЋь∞ьЇђ Unicode іъ¬лµг э„й≤ќ э“їЄц„” э„йµƒ„÷Јы°£offset ≤ќ э «Є√„” э„йµЏ“їЄціъ¬лµгµƒЋч“э£ђcount ≤ќ э÷Єґ®„” э„йµƒ≥§ґ»°£љЂЄ√„” э„йµƒƒЏ»Ё„™їїќ™ char£їЇу–шґ‘ int э„йµƒ–ёЄƒ≤їїб”∞ѕм–¬ііљ®µƒ„÷ЈыіЃ°£
codePoints - „чќ™ Unicode іъ¬лµгµƒ‘іµƒ э„й°£offset - ≥х Љ∆Ђ“∆Ѕњ°£count - ≥§ґ»°£
IllegalArgumentException - »зєы‘Џ codePoints ÷–ЈҐѕ÷»ќЇќќё–Іµƒ Unicode іъ¬лµг
IndexOutOfBoundsException - »зєы offset ЇЌ count ≤ќ эЋч“э„÷Јы≥ђ≥ц codePoints э„йµƒЈґќІ°£
@Deprecated
public String(byte[] ascii,
int hibyte,
int offset,
int count)
Charset°Ґ„÷ЈыЉѓ√ы≥∆£ђїт є”√∆љћ®ƒђ»ѕ„÷ЈыЉѓµƒ String єє‘мЈљЈ®°£
String£ђЋь «ЄщЊЁ“їЄц 8 ќї’ы э÷µ э„йµƒ„” э„йєє‘мµƒ°£
offset ≤ќ э «Є√„” э„йµƒµЏ“їЄц byte µƒЋч“э£ђcount ≤ќ э÷Єґ®„” э„йµƒ≥§ґ»°£
„” э„й÷–µƒ√њЄц byte ґЉ∞і’’…ѕ цЈљЈ®„™їїќ™ char°£
ascii - “™„™їїќ™„÷Јыµƒ byte°£hibyte - √њЄц 16 ќї Unicode іъ¬лµ•‘™µƒ«∞ 8 ќї°£offset - ≥х Љ∆Ђ“∆Ѕњ°£count - ≥§ґ»°£
IndexOutOfBoundsException - »зєы offset їт count ≤ќ эќё–І°£String(byte[], int),
String(byte[], int, int, java.lang.String),
String(byte[], int, int, java.nio.charset.Charset),
String(byte[], int, int),
String(byte[], java.lang.String),
String(byte[], java.nio.charset.Charset),
String(byte[])
@Deprecated
public String(byte[] ascii,
int hibyte)
Charset°Ґ„÷ЈыЉѓ√ы≥∆£ђїт є”√∆љћ®ƒђ»ѕ„÷ЈыЉѓµƒ String єє‘мЈљЈ®°£
String£ђЋь∞ьЇђЄщЊЁ“їЄц 8 ќї’ы э÷µ э„йєє‘мµƒ„÷Јы°£Ћщµ√„÷ЈыіЃ÷–µƒ√њЄц„÷Јы c ґЉ «ЄщЊЁ byte э„й÷–µƒѕа”¶„йЉю b єє‘мµƒ£ђ»зѕ¬Ћщ Њ£Ї
c == (char)(((hibyte & 0xff) << 8)
| (b & 0xff))
ascii - “™„™їїќ™„÷Јыµƒ byte°£hibyte - √њЄц 16 ќї Unicode іъ¬лµ•‘™µƒ«∞ 8 ќї°£String(byte[], int, int, java.lang.String),
String(byte[], int, int, java.nio.charset.Charset),
String(byte[], int, int),
String(byte[], java.lang.String),
String(byte[], java.nio.charset.Charset),
String(byte[])
public String(byte[] bytes,
int offset,
int length,
String charsetName)
throws UnsupportedEncodingException
String°£–¬ String µƒ≥§ґ» «“їЄц„÷ЈыЉѓЇѓ э£ђ“тіЋњ…ƒ№≤їµ»”Џ„” э„йµƒ≥§ґ»°£
µ±Єшґ® byte ‘ЏЄшґ®„÷ЈыЉѓ÷–ќё–Іµƒ«йњцѕ¬£ђіЋєє‘мЈљЈ®µƒ––ќ™√ї”–÷Єґ®°£»зєы–и“™ґ‘љв¬лєэ≥ћљш––ЄьґањЎ÷∆£ђ‘т”¶Є√ є”√ CharsetDecoder ја°£
bytes - “™љв¬лќ™„÷Јыµƒ byteoffset - “™љв¬лµƒµЏ“їЄц byte µƒЋч“эlength - “™љв¬лµƒ byte эcharsetName - №÷І≥÷ charset µƒ√ы≥∆
UnsupportedEncodingException - »зєы÷Єґ®µƒ„÷ЈыЉѓ≤ї №÷І≥÷
IndexOutOfBoundsException - »зєы offset ЇЌ length ≤ќ эЋч“э„÷Јы≥ђ≥ц bytes э„йµƒЈґќІ
public String(byte[] bytes,
int offset,
int length,
Charset charset)
String°£–¬ String µƒ≥§ґ» «„÷ЈыЉѓµƒЇѓ э£ђ“тіЋњ…ƒ№≤їµ»”Џ„” э„йµƒ≥§ґ»°£
іЋЈљЈ®„№ « є”√іЋ„÷ЈыЉѓµƒƒђ»ѕћжіъ„÷ЈыіЃћжіъінќу д»л (malformed-input) ЇЌ≤їњ…”≥…д„÷Јы (unmappable-character) –тЅ–°£»зєы–и“™ґ‘љв¬лєэ≥ћљш––ЄьґањЎ÷∆£ђ‘т”¶Є√ є”√ CharsetDecoder ја°£
bytes - “™љв¬лќ™„÷Јыµƒ byteoffset - “™љв¬лµƒµЏ“їЄц byte µƒЋч“эlength - “™љв¬лµƒ byte эcharset - ”√јіљв¬л bytes µƒ charset
IndexOutOfBoundsException - »зєы offset ЇЌ length ≤ќ эЋч“э„÷Јы≥ђ≥ц bytes э„йµƒ±яљз
public String(byte[] bytes,
String charsetName)
throws UnsupportedEncodingException
String°£–¬ String µƒ≥§ґ» «„÷ЈыЉѓµƒЇѓ э£ђ“тіЋњ…ƒ№≤їµ»”Џ byte э„йµƒ≥§ґ»°£
µ±Єшґ® byte ‘ЏЄшґ®„÷ЈыЉѓ÷–ќё–Іµƒ«йњцѕ¬£ђіЋєє‘мЈљЈ®µƒ––ќ™√ї”–÷Єґ®°£»зєы–и“™ґ‘љв¬лєэ≥ћљш––ЄьґањЎ÷∆£ђ‘т”¶Є√ є”√ CharsetDecoder ја°£
bytes - “™љв¬лќ™„÷Јыµƒ bytecharsetName - №÷І≥÷µƒ charset µƒ√ы≥∆
UnsupportedEncodingException - »зєы÷Єґ®„÷ЈыЉѓ≤ї №÷І≥÷
public String(byte[] bytes,
Charset charset)
String°£–¬ String µƒ≥§ґ» «„÷ЈыЉѓµƒЇѓ э£ђ“тіЋњ…ƒ№≤їµ»”Џ byte э„йµƒ≥§ґ»°£
іЋЈљЈ®„№ « є”√іЋ„÷ЈыЉѓµƒƒђ»ѕћжіъ„÷ЈыіЃћжіъінќу д»лЇЌ≤їњ…”≥…д„÷Јы–тЅ–°£»зєы–и“™ґ‘љв¬лєэ≥ћљш––ЄьґањЎ÷∆£ђ‘т”¶Є√ є”√ CharsetDecoder ја°£
bytes - “™љв¬лќ™„÷Јыµƒ bytecharset - “™”√јіљв¬л bytes µƒ charset
public String(byte[] bytes,
int offset,
int length)
String°£–¬ String µƒ≥§ґ» «„÷ЈыЉѓµƒЇѓ э£ђ“тіЋњ…ƒ№≤їµ»”ЏЄ√„” э„йµƒ≥§ґ»°£
µ±Єшґ® byte ‘ЏЄшґ®„÷ЈыЉѓ÷–ќё–Іµƒ«йњцѕ¬£ђіЋєє‘мЈљЈ®µƒ––ќ™√ї”–÷Єґ®°£»зєы–и“™ґ‘љв¬лєэ≥ћљш––ЄьґањЎ÷∆£ђ‘т”¶Є√ є”√ CharsetDecoder ја°£
bytes - “™љв¬лќ™„÷Јыµƒ byteoffset - “™љв¬лµƒµЏ“їЄц byte µƒЋч“эlength - “™љв¬лµƒ byte э
IndexOutOfBoundsException - »зєы offset ЇЌ length ≤ќ эЋч“э„÷Јы≥ђ≥ц bytes э„йµƒЈґќІpublic String(byte[] bytes)
String°£–¬ String µƒ≥§ґ» «„÷ЈыЉѓµƒЇѓ э£ђ“тіЋњ…ƒ№≤їµ»”Џ byte э„йµƒ≥§ґ»°£
µ±Єшґ® byte ‘ЏЄшґ®„÷ЈыЉѓ÷–ќё–Іµƒ«йњцѕ¬£ђіЋєє‘мЈљЈ®µƒ––ќ™√ї”–÷Єґ®°£»зєы–и“™ґ‘љв¬лєэ≥ћљш––ЄьґањЎ÷∆£ђ‘т”¶Є√ є”√ CharsetDecoder ја°£
bytes - “™љв¬лќ™„÷Јыµƒ bytepublic String(StringBuffer buffer)
buffer - “їЄц StringBufferpublic String(StringBuilder builder)
ћбє©іЋєє‘мЈљЈ® «ќ™ЅЋЉтїѓµљ StringBuilder µƒ«®“∆°£Ќ®єэ toString ЈљЈ®і”„÷ЈыіЃ…ъ≥…∆ч÷–їс»°„÷ЈыіЃњ…ƒ№‘Ћ––µƒЄьњм£ђ“тіЋЌ®≥£„чќ™ „—°°£
builder - “їЄц StringBuilder| ЈљЈ®ѕкѕЄ–≈ѕҐ |
|---|
public int length()
CharSequence ÷–µƒ lengthpublic boolean isEmpty()
length() ќ™ 0 ±ЈµїЎ true°£
length() ќ™ 0£ђ‘тЈµїЎ true£їЈс‘тЈµїЎ false°£public char charAt(int index)
char ÷µ°£Ћч“эЈґќІќ™і” 0 µљ length() - 1°£–тЅ–µƒµЏ“їЄц char ÷µќї”ЏЋч“э 0 і¶£ђµЏґюЄцќї”ЏЋч“э 1 і¶£ђ“јіЋјаЌ∆£ђ’вјаЋ∆”Џ э„йЋч“э°£
»зєыЋч“э÷Єґ®µƒ char ÷µ «іъјнѕо£ђ‘тЈµїЎіъјнѕо÷µ°£
CharSequence ÷–µƒ charAtindex - char ÷µµƒЋч“э°£
char ÷µ°£µЏ“їЄц char ÷µќї”ЏЋч“э 0 і¶°£
IndexOutOfBoundsException - »зєы index ≤ќ эќ™ЄЇїт–°”ЏіЋ„÷ЈыіЃµƒ≥§ґ»°£public int codePointAt(int index)
char ÷µ£®Unicode іъ¬лµ•‘™£©£ђ∆дЈґќІі” 0 µљ length() - 1°£
»зєыЄшґ®Ћч“э÷Єґ®µƒ char ÷µ ф”ЏЄяіъјнѕоЈґќІ£ђ‘тЇу–шЋч“э–°”ЏіЋ String µƒ≥§ґ»£ї»зєыЇу–шЋч“эі¶µƒ char ÷µ ф”ЏµЌіъјнѕоЈґќІ£ђ‘тЈµїЎЄ√іъјнѕоґ‘ѕа”¶µƒ‘ц≤єіъ¬лµг°£Јс‘т£ђЈµїЎЄшґ®Ћч“эі¶µƒ char ÷µ°£
index - char ÷µµƒЋч“э
index і¶„÷Јыµƒіъ¬лµг÷µ
IndexOutOfBoundsException - »зєы index ≤ќ эќ™ЄЇїт–°”ЏіЋ„÷ЈыіЃµƒ≥§ґ»°£public int codePointBefore(int index)
char ÷µ£®Unicode іъ¬лµ•‘™£©£ђ∆дЈґќІі” 1 µљ length°£
»зєы (index - 1) і¶µƒ char ÷µ ф”ЏµЌіъјнѕоЈґќІ£ђ‘т (index - 2) ќ™Ј«ЄЇ£ї»зєы (index - 2) і¶µƒ char ÷µ ф”ЏЄяµЌјнѕоЈґќІ£ђ‘тЈµїЎЄ√іъјнѕоґ‘µƒ‘ц≤єіъ¬лµг÷µ°£»зєы index - 1 і¶µƒ char ÷µ «ќі≈дґ‘µƒµЌ£®Єя£©іъјнѕо£ђ‘тЈµїЎіъјнѕо÷µ°£
index - ”¶ЈµїЎµƒіъ¬лµг÷ЃЇуµƒЋч“э
IndexOutOfBoundsException - »зєы index ≤ќ э–°”Џ 1 їтіу”ЏіЋ„÷ЈыіЃµƒ≥§ґ»°£
public int codePointCount(int beginIndex,
int endIndex)
String µƒ÷Єґ®ќƒ±ЊЈґќІ÷–µƒ Unicode іъ¬лµг э°£ќƒ±ЊЈґќІ Љ”Џ÷Єґ®µƒ beginIndex£ђ“ї÷±µљЋч“э endIndex - 1 і¶µƒ char°£“тіЋ£ђЄ√ќƒ±ЊЈґќІµƒ≥§ґ»£®”√ char ±н Њ£© « endIndex-beginIndex°£Є√ќƒ±ЊЈґќІƒЏ√њЄцќі≈дґ‘µƒіъјнѕоЉ∆ќ™“їЄціъ¬лµг°£
beginIndex - ќƒ±ЊЈґќІµƒµЏ“їЄц char µƒЋч“э°£endIndex - ќƒ±ЊЈґќІµƒ„оЇу“їЄц char ÷ЃЇуµƒЋч“э°£
IndexOutOfBoundsException - »зєы beginIndex ќ™ЄЇ£ђїт endIndex іу”ЏіЋ String µƒ≥§ґ»£ђїт beginIndex іу”Џ endIndex°£
public int offsetByCodePoints(int index,
int codePointOffset)
String ÷–і”Єшґ®µƒ index і¶∆Ђ“∆ codePointOffset Єціъ¬лµгµƒЋч“э°£ќƒ±ЊЈґќІƒЏ”… index ЇЌ codePointOffset Єшґ®µƒќі≈дґ‘іъјнѕоЄчЉ∆ќ™“їЄціъ¬лµг°£
index - “™∆Ђ“∆µƒЋч“эcodePointOffset - іъ¬лµг÷–µƒ∆Ђ“∆Ѕњ
String µƒЋч“э
IndexOutOfBoundsException - »зєы index ќ™ЄЇїтіу”ЏіЋ String µƒ≥§ґ»£їїт’я codePointOffset ќ™’э£ђ«““‘ index њ™ЌЈ„”„÷ЈыіЃµƒіъ¬лµг±» codePointOffset …ў£ї»зєы codePointOffset ќ™ЄЇ£ђ«“ index «∞√ж„”„÷ЈыіЃµƒіъ¬лµг±» codePointOffset µƒЊшґ‘÷µ…ў°£
public void getChars(int srcBegin,
int srcEnd,
char[] dst,
int dstBegin)
“™Єі÷∆µƒµЏ“їЄц„÷Јыќї”ЏЋч“э srcBegin і¶£ї“™Єі÷∆µƒ„оЇу“їЄц„÷Јыќї”ЏЋч“э srcEnd-1 і¶£®“тіЋ“™Єі÷∆µƒ„÷Јы„№ э « srcEnd-srcBegin£©°£“™Єі÷∆µљ dst „” э„йµƒ„÷Јыі”Ћч“э dstBegin і¶њ™ Љ£ђ≤Ґљб ш”ЏЋч“э£Ї
dstbegin + (srcEnd-srcBegin) - 1
srcBegin - „÷ЈыіЃ÷–“™Єі÷∆µƒµЏ“їЄц„÷ЈыµƒЋч“э°£srcEnd - „÷ЈыіЃ÷–“™Єі÷∆µƒ„оЇу“їЄц„÷Јы÷ЃЇуµƒЋч“э°£dst - ƒњ±к э„й°£dstBegin - ƒњ±к э„й÷–µƒ∆р Љ∆Ђ“∆Ѕњ°£
IndexOutOfBoundsException - »зєыѕ¬Ѕ–»ќЇќ“їѕоќ™ true£Ї
srcBegin ќ™ЄЇ°£
srcBegin іу”Џ srcEnd
srcEnd іу”ЏіЋ„÷ЈыіЃµƒ≥§ґ»
dstBegin ќ™ЄЇ
dstBegin+(srcEnd-srcBegin) іу”Џ dst.length
@Deprecated
public void getBytes(int srcBegin,
int srcEnd,
byte[] dst,
int dstBegin)
getBytes() ЈљЈ®£ђЄ√ЈљЈ® є”√∆љћ®µƒƒђ»ѕ„÷ЈыЉѓ°£
“™Єі÷∆µƒµЏ“їЄц„÷Јыќї”ЏЋч“э srcBegin і¶£ї“™Єі÷∆µƒ„оЇу“їЄц„÷Јыќї”ЏЋч“э srcEnd-1 і¶°£“™Єі÷∆µƒ„÷Јы„№ эќ™ srcEnd-srcBegin°£љЂ„™їїќ™ byte µƒ„÷ЈыЄі÷∆µљ dst µƒ„” э„й÷–£ђі”Ћч“э dstBegin і¶њ™ Љ£ђ≤Ґљб ш”ЏЋч“э£Ї
dstbegin + (srcEnd-srcBegin) - 1
srcBegin - „÷ЈыіЃ÷–“™Єі÷∆µƒµЏ“їЄц„÷ЈыµƒЋч“эsrcEnd - „÷ЈыіЃ÷–“™Єі÷∆µƒ„оЇу“їЄц„÷Јы÷ЃЇуµƒЋч“эdst - ƒњ±к э„йdstBegin - ƒњ±к э„й÷–µƒ∆р Љ∆Ђ“∆Ѕњ
IndexOutOfBoundsException - »зєыѕ¬Ѕ–»ќЇќ“їѕоќ™ true£Ї
srcBegin ќ™ЄЇ
srcBegin іу”Џ srcEnd
srcEnd іу”ЏіЋ String µƒ≥§ґ»
dstBegin ќ™ЄЇ
dstBegin+(srcEnd-srcBegin) іу”Џ dst.length
public byte[] getBytes(String charsetName)
throws UnsupportedEncodingException
String ±а¬лќ™ byte –тЅ–£ђ≤ҐљЂљбєыіжіҐµљ“їЄц–¬µƒ byte э„й÷–°£
µ±іЋ„÷ЈыіЃ≤їƒ№ є”√Єшґ®µƒ„÷ЈыЉѓ±а¬л ±£ђіЋЈљЈ®µƒ––ќ™√ї”–÷Єґ®°£»зєы–и“™ґ‘±а¬лєэ≥ћљш––ЄьґањЎ÷∆£ђ‘т”¶Є√ є”√ CharsetEncoder ја°£
charsetName - №÷І≥÷µƒ charset √ы≥∆
UnsupportedEncodingException - »зєы÷Єґ®µƒ„÷ЈыЉѓ≤ї №÷І≥÷public byte[] getBytes(Charset charset)
String ±а¬лµљ byte –тЅ–£ђ≤ҐљЂљбєыіжіҐµљ–¬µƒ byte э„й°£
іЋЈљЈ®„№ « є”√іЋ„÷ЈыЉѓµƒƒђ»ѕћжіъ byte э„йћжіъінќу д»лЇЌ≤їњ…”≥…д„÷Јы–тЅ–°£»зєы–и“™ґ‘±а¬лєэ≥ћљш––ЄьґањЎ÷∆£ђ‘т”¶Є√ є”√ CharsetEncoder ја°£
charset - ”√”Џ±а¬л String µƒ Charset
public byte[] getBytes()
String ±а¬лќ™ byte –тЅ–£ђ≤ҐљЂљбєыіжіҐµљ“їЄц–¬µƒ byte э„й÷–°£
µ±іЋ„÷ЈыіЃ≤їƒ№ є”√ƒђ»ѕµƒ„÷ЈыЉѓ±а¬л ±£ђіЋЈљЈ®µƒ––ќ™√ї”–÷Єґ®°£»зєы–и“™ґ‘±а¬лєэ≥ћљш––ЄьґањЎ÷∆£ђ‘т”¶Є√ є”√ CharsetEncoder ја°£
public boolean equals(Object anObject)
null£ђ≤Ґ«“ «”ліЋґ‘ѕу±н ЊѕаЌђ„÷Јы–тЅ–µƒ String ґ‘ѕу ±£ђљбєы≤≈ќ™ true°£
Object ÷–µƒ equalsanObject - ”ліЋ String љш––±»љѕµƒґ‘ѕу°£
String ”ліЋ String ѕаµ»£ђ‘тЈµїЎ true£їЈс‘тЈµїЎ false°£compareTo(String),
equalsIgnoreCase(String)public boolean contentEquals(StringBuffer sb)
StringBuffer ±»љѕ°£µ±«“љцµ±іЋ String ”л÷Єґ® StringBuffer ±н ЊѕаЌђµƒ„÷Јы–тЅ– ±£ђљбєы≤≈ќ™ true°£
sb - “™”ліЋ String ±»љѕµƒ StringBuffer°£
String ”л÷Єґ® StringBuffer ±н ЊѕаЌђµƒ„÷Јы–тЅ–£ђ‘тЈµїЎ true£їЈс‘тЈµїЎ false°£public boolean contentEquals(CharSequence cs)
CharSequence ±»љѕ°£µ±«“љцµ±іЋ String ”л÷Єґ®–тЅ–±н ЊѕаЌђµƒ char ÷µ–тЅ– ±£ђљбєы≤≈ќ™ true°£
cs - “™”ліЋ String ±»љѕµƒ–тЅ–
String ”л÷Єґ®–тЅ–±н ЊѕаЌђµƒ char ÷µ–тЅ–£ђ‘тЈµїЎ true£їЈс‘тЈµїЎ false°£public boolean equalsIgnoreCase(String anotherString)
String ”лЅн“їЄц String ±»љѕ£ђ≤їњЉ¬«іу–°–і°£»зєыЅљЄц„÷ЈыіЃµƒ≥§ґ»ѕаЌђ£ђ≤Ґ«“∆д÷–µƒѕа”¶„÷ЈыґЉѕаµ»£®Їц¬‘іу–°–і£©£ђ‘т»ѕќ™’вЅљЄц„÷ЈыіЃ «ѕаµ»µƒ°£
‘ЏЇц¬‘іу–°–іµƒ«йњцѕ¬£ђ»зєыѕ¬Ѕ–÷Ѕ…ў“їѕоќ™ true£ђ‘т»ѕќ™ c1 ЇЌ c2 ’вЅљЄц„÷ЈыѕаЌђ°£
== ‘ЋЋгЈыљш––±»љѕ£©°£
Character.toUpperCase(char) …ъ≥…ѕаЌђµƒљбєы°£
Character.toLowerCase(char) …ъ≥…ѕаЌђµƒљбєы°£
anotherString - ”ліЋ String љш––±»љѕµƒ String°£
null£ђ«“’вЅљЄц String ѕаµ»£®Їц¬‘іу–°–і£©£ђ‘тЈµїЎ true£їЈс‘тЈµїЎ false°£equals(Object)public int compareTo(String anotherString)
String ґ‘ѕу±н Њµƒ„÷Јы–тЅ–”л≤ќ э„÷ЈыіЃЋщ±н Њµƒ„÷Јы–тЅ–љш––±»љѕ°£»зєы∞і„÷µдЋ≥–тіЋ String ґ‘ѕуќї”Џ≤ќ э„÷ЈыіЃ÷Ѓ«∞£ђ‘т±»љѕљбєыќ™“їЄцЄЇ’ы э°£»зєы∞і„÷µдЋ≥–тіЋ String ґ‘ѕуќї”Џ≤ќ э„÷ЈыіЃ÷ЃЇу£ђ‘т±»љѕљбєыќ™“їЄц’э’ы э°£»зєы’вЅљЄц„÷ЈыіЃѕаµ»£ђ‘тљбєыќ™ 0£їcompareTo ÷ї‘ЏЈљЈ® equals(Object) ЈµїЎ true ±≤≈ЈµїЎ 0°£
’в «„÷µд≈≈–тµƒґ®“е°£»зєы’вЅљЄц„÷ЈыіЃ≤їЌђ£ђƒ«√іЋь√«“™√і‘Џƒ≥ЄцЋч“эі¶µƒ„÷Јы≤їЌђ£®Є√Ћч“эґ‘ґю’яЊщќ™”––ІЋч“э£©£ђ“™√і≥§ґ»≤їЌђ£ђїт’яЌђ ±Њя±Є’вЅљ÷÷«йњц°£»зєыЋь√«‘Џ“їЄцїтґаЄцЋч“эќї÷√…ѕµƒ„÷Јы≤їЌђ£ђЉў…и k «’вјаЋч“эµƒ„о–°÷µ£ї‘т‘Џќї÷√ k …ѕЊя”–љѕ–°÷µµƒƒ«Єц„÷ЈыіЃ£® є”√ < ‘ЋЋгЈы»Јґ®£©£ђ∆д„÷µдЋ≥–т‘Џ∆дЋы„÷ЈыіЃ÷Ѓ«∞°£‘Џ’в÷÷«йњцѕ¬£ђcompareTo ЈµїЎ’вЅљЄц„÷ЈыіЃ‘Џќї÷√ k і¶ЅљЄцchar ÷µµƒ≤о£ђЉі÷µ£Ї
»зєы√ї”–„÷Јы≤їЌђµƒЋч“эќї÷√£ђ‘тљѕґћ„÷ЈыіЃµƒ„÷µдЋ≥–т‘Џљѕ≥§„÷ЈыіЃ÷Ѓ«∞°£‘Џ’в÷÷«йњцѕ¬£ђthis.charAt(k)-anotherString.charAt(k)
compareTo ЈµїЎ’вЅљЄц„÷ЈыіЃ≥§ґ»µƒ≤о£ђЉі÷µ£Ї
this.length()-anotherString.length()
Comparable<String> ÷–µƒ compareToanotherString - “™±»љѕµƒ String°£
0£ї»зєыіЋ„÷ЈыіЃ∞і„÷µдЋ≥–т–°”Џ„÷ЈыіЃ≤ќ э£ђ‘тЈµїЎ“їЄц–°”Џ 0 µƒ÷µ£ї»зєыіЋ„÷ЈыіЃ∞і„÷µдЋ≥–тіу”Џ„÷ЈыіЃ≤ќ э£ђ‘тЈµїЎ“їЄціу”Џ 0 µƒ÷µ°£public int compareToIgnoreCase(String str)
compareTo Ћщµ√ЈыЇ≈ѕаЌђ£ђєжЈґїѓ„÷ЈыіЃµƒіу–°–і≤о“м“—Ќ®єэґ‘√њЄц„÷Јыµч”√ Character.toLowerCase(Character.toUpperCase(character)) ѕы≥э°£
„Ґ“в£ђіЋЈљЈ®≤ї њЉ¬«”п—‘їЈЊ≥£ђ“тіЋњ…ƒ№µЉ÷¬‘Џƒ≥–©”п—‘їЈЊ≥÷–µƒ≈≈–т–Ієы≤їјнѕл°£java.text ∞ьћбє© Collators Ќк≥…”л”п—‘їЈЊ≥”–єЎµƒ≈≈–т°£
str - “™±»љѕµƒ String°£
Collator.compare(String, String)
public boolean regionMatches(int toffset,
String other,
int ooffset,
int len)
љЂіЋ String ґ‘ѕуµƒ“їЄц„”„÷ЈыіЃ”л≤ќ э other µƒ“їЄц„”„÷ЈыіЃљш––±»љѕ°£»зєы’вЅљЄц„”„÷ЈыіЃ±н ЊѕаЌђµƒ„÷Јы–тЅ–£ђ‘тљбєыќ™ true°£“™±»љѕµƒіЋ String ґ‘ѕуµƒ„”„÷ЈыіЃі”Ћч“э toffset і¶њ™ Љ£ђ≥§ґ»ќ™ len°£“™±»љѕµƒ other µƒ„”„÷ЈыіЃі”Ћч“э ooffset і¶њ™ Љ£ђ≥§ґ»ќ™ len°£µ±«“љцµ±ѕ¬Ѕ–÷Ѕ…ў“їѕоќ™ true ±£ђљбєы≤≈ќ™ false £Ї
toffset - „÷ЈыіЃ÷–„”«ш”тµƒ∆р Љ∆Ђ“∆Ѕњ°£other - „÷ЈыіЃ≤ќ э°£ooffset - „÷ЈыіЃ≤ќ э÷–„”«ш”тµƒ∆р Љ∆Ђ“∆Ѕњ°£len - “™±»љѕµƒ„÷Јы э°£
true£їЈс‘тЈµїЎ false°£
public boolean regionMatches(boolean ignoreCase,
int toffset,
String other,
int ooffset,
int len)
љЂіЋ String ґ‘ѕуµƒ„”„÷ЈыіЃ”л≤ќ э other µƒ„”„÷ЈыіЃљш––±»љѕ°£»зєы’вЅљЄц„”„÷ЈыіЃ±н ЊѕаЌђµƒ„÷Јы–тЅ–£ђ‘тљбєыќ™ true£ђµ±«“љцµ± ignoreCase ќ™ true ±Їц¬‘іу–°–і°£“™±»љѕµƒіЋ String ґ‘ѕуµƒ„”„÷ЈыіЃі”Ћч“э toffset і¶њ™ Љ£ђ≥§ґ»ќ™ len°£“™±»љѕµƒ other µƒ„”„÷ЈыіЃі”Ћч“э ooffset і¶њ™ Љ£ђ≥§ґ»ќ™ len°£µ±«“љцµ±ѕ¬Ѕ–÷Ѕ…ў“їѕоќ™ true ±£ђљбєы≤≈ќ™ false£Ї
this.charAt(toffset+k) != other.charAt(ooffset+k)
Character.toLowerCase(this.charAt(toffset+k)) !=
Character.toLowerCase(other.charAt(ooffset+k))
Character.toUpperCase(this.charAt(toffset+k)) !=
Character.toUpperCase(other.charAt(ooffset+k))
ignoreCase - »зєыќ™ true£ђ‘т±»љѕ„÷Јы ±Їц¬‘іу–°–і°£toffset - іЋ„÷ЈыіЃ÷–„”«ш”тµƒ∆р Љ∆Ђ“∆Ѕњ°£other - „÷ЈыіЃ≤ќ э°£toffset - „÷ЈыіЃ≤ќ э÷–„”«ш”тµƒ∆р Љ∆Ђ“∆Ѕњ°£len - “™±»љѕµƒ„÷Јы э°£
true£їЈс‘тЈµїЎ false°£ «ЈсЌк»Ђ∆•≈дїтњЉ¬«іу–°–і»°Њц”Џ ignoreCase ≤ќ э°£
public boolean startsWith(String prefix,
int toffset)
prefix - «∞„Ї°£toffset - ‘ЏіЋ„÷ЈыіЃ÷–њ™ Љ≤й’“µƒќї÷√°£
toffset і¶њ™ Љµƒ„”„÷ЈыіЃ«∞„Ї£ђ‘тЈµїЎ true£їЈс‘тЈµїЎ false°£»зєы toffset ќ™ЄЇїтіу”ЏіЋ String ґ‘ѕуµƒ≥§ґ»£ђ‘тљбєыќ™ false£їЈс‘тљбєы”л“‘ѕ¬±ніп љµƒљбєыѕаЌђ£Ї
this.substring(toffset).startsWith(prefix)
public boolean startsWith(String prefix)
prefix - «∞„Ї°£
true£їЈс‘тЈµїЎ false°£їє“™„Ґ“в£ђ»зєы≤ќ э «њ’„÷ЈыіЃ£ђїт’яµ»”ЏіЋ String ґ‘ѕу£®”√ equals(Object) ЈљЈ®»Јґ®£©£ђ‘тЈµїЎ true°£public boolean endsWith(String suffix)
suffix - Їу„Ї°£
true£їЈс‘тЈµїЎ false°£„Ґ“в£ђ»зєы≤ќ э «њ’„÷ЈыіЃ£ђїт’яµ»”ЏіЋ String ґ‘ѕу£®”√ equals(Object) ЈљЈ®»Јґ®£©£ђ‘тљбєыќ™ true°£public int hashCode()
String ґ‘ѕуµƒєюѕ£¬лЄщЊЁ“‘ѕ¬єЂ љЉ∆Ћг£Ї
є”√s[0]*31^(n-1) + s[1]*31^(n-2) + ... + s[n-1]
int ЋгЈ®£ђ’вјп s[i] «„÷ЈыіЃµƒµЏ i Єц„÷Јы£ђn «„÷ЈыіЃµƒ≥§ґ»£ђ^ ±н Њ«у√Ё°££®њ’„÷ЈыіЃµƒєюѕ£÷µќ™ 0°££©
Object ÷–µƒ hashCodeObject.equals(java.lang.Object),
Hashtablepublic int indexOf(int ch)
String ґ‘ѕу±н Њµƒ„÷Јы–тЅ–÷–≥цѕ÷÷µќ™ ch µƒ„÷Јы£ђ‘тЈµїЎµЏ“їіќ≥цѕ÷Є√„÷ЈыµƒЋч“э£®“‘ Unicode іъ¬лµ•‘™±н Њ£©°£ґ‘”Џ 0 µљ 0xFFFF£®∞ьј® 0 ЇЌ 0xFFFF£©ЈґќІƒЏµƒ ch µƒ÷µ£ђЈµїЎ÷µ «
ќ™ true µƒ„о–° k ÷µ°£ґ‘”Џ∆дЋыthis.charAt(k) == ch
ch ÷µ£ђЈµїЎ÷µ «
ќ™ true „о–° k ÷µ°£ќё¬џƒƒ÷÷«йњц£ђ»зєыіЋ„÷ЈыіЃ÷–√ї”–’в—щµƒ„÷Јы£ђ‘тЈµїЎthis.codePointAt(k) == ch
-1°£
ch - “їЄц„÷Јы£®Unicode іъ¬лµг£©°£
-1°£
public int indexOf(int ch,
int fromIndex)
‘ЏіЋ String ґ‘ѕу±н Њµƒ„÷Јы–тЅ–÷–£ђ»зєыіш”–÷µ ch µƒ„÷ЈыµƒЋч“э≤ї–°”Џ fromIndex£ђ‘тЈµїЎµЏ“їіќ≥цѕ÷Є√÷µµƒЋч“э°£ґ‘”Џ 0 µљ 0xFFFF£®∞ьј® 0 ЇЌ 0xFFFF£©ЈґќІƒЏµƒ ch ÷µ£ђЈµїЎ÷µ «
ќ™ true µƒ„о–° k ÷µ°£ґ‘”Џ∆дЋы(this.charAt(k) == ch) && (k >= fromIndex)
ch ÷µ£ђЈµїЎ÷µ «
ќ™ true µƒ„о–° k ÷µ°£ќё¬џƒƒ÷÷«йњц£ђ»зєыіЋ„÷ЈыіЃ÷–(this.codePointAt(k) == ch) && (k >= fromIndex)
fromIndex їт÷ЃЇуµƒќї÷√√ї”–’в—щµƒ„÷Јы≥цѕ÷£ђ‘тЈµїЎ -1°£
fromIndex µƒ÷µ√ї”–ѕё÷∆°£»зєыЋьќ™ЄЇ£ђ‘т”лЋьќ™ 0 µƒ–ІєыЌђ—щ£ЇљЂЋ—Ћч’ыЄц„÷ЈыіЃ°£»зєыЋьіу”ЏіЋ„÷ЈыіЃµƒ≥§ґ»£ђ‘т”лЋьµ»”ЏіЋ„÷ЈыіЃ≥§ґ»µƒ–ІєыѕаЌђ£ЇЈµїЎ -1°£
Ћщ”–Ћч“эґЉ‘Џ char ÷µ÷–÷Єґ®£®Unicode іъ¬лµ•‘™£©°£
ch - “їЄц„÷Јы£®Unicode іъ¬лµг£©°£fromIndex - њ™ ЉЋ—ЋчµƒЋч“э°£
fromIndex µƒ„÷ЈыµƒЋч“э£ї»зєыќі≥цѕ÷Є√„÷Јы£ђ‘тЈµїЎ -1°£public int lastIndexOf(int ch)
ch µƒ÷µ£ђЈµїЎµƒЋч“э£®Unicode іъ¬лµ•‘™£© «
ќ™ true „оіу k ÷µ°£ґ‘”Џ∆дЋыthis.charAt(k) == ch
ch ÷µ£ђЈµїЎ÷µ «
ќ™ true µƒ„оіу k ÷µ°£ќё¬џƒƒ÷÷«йњц£ђ»зєыіЋ„÷ЈыіЃ÷–√ї”–’в—щµƒ„÷Јы≥цѕ÷£ђ‘тЈµїЎthis.codePointAt(k) == ch
-1°£і”„оЇу“їЄц„÷Јыњ™ ЉЈіѕтЋ—ЋчіЋ String°£
ch - “їЄц„÷Јы£®Unicode іъ¬лµг£©°£
-1°£
public int lastIndexOf(int ch,
int fromIndex)
ch ÷µ£ђЈµїЎµƒЋч“э «
ќ™ true µƒ„оіу k ÷µ°£ґ‘”Џ(this.charAt(k) == ch) && (k <= fromIndex)
ch µƒ∆дЋы÷µ£ђЈµїЎ÷µ «
ќ™ true µƒ„оіу k ÷µ°£ќё¬џƒƒ÷÷«йњц£ђ»зєыіЋ„÷ЈыіЃ÷–(this.codePointAt(k) == ch) && (k <= fromIndex)
fromIndex їт÷Ѓ«∞µƒќї÷√√ї”–’в—щµƒ„÷Јы≥цѕ÷£ђ‘тЈµїЎ -1°£
Ћщ”–µƒЋч“эґЉ“‘ char ÷µ÷Єґ®£®Unicode іъ¬лµ•‘™£©°£
ch - “їЄц„÷Јы£®Unicode іъ¬лµг£©°£fromIndex - њ™ ЉЋ—ЋчµƒЋч“э°£fromIndex µƒ÷µ√ї”–ѕё÷∆°£»зєыЋьіу”Џµ»”ЏіЋ„÷ЈыіЃµƒ≥§ґ»£ђ‘т”лЋь–°”ЏіЋ„÷ЈыіЃ≥§ґ»Љх 1 µƒ–ІєыѕаЌђ£ЇљЂЋ—Ћч’ыЄц„÷ЈыіЃ°£»зєыЋьќ™ЄЇ£ђ‘т”лЋьќ™ -1 µƒ–ІєыѕаЌђ£ЇЈµїЎ -1°£
fromIndex£©÷–„оЇу“їіќ≥цѕ÷Є√„÷ЈыµƒЋч“э£ї»зєы‘ЏЄ√µг÷Ѓ«∞ќі≥цѕ÷Є√„÷Јы£ђ‘тЈµїЎ -1°£public int indexOf(String str)
ќ™this.startsWith(str, k)
true µƒ„о–° k ÷µ°£
str - »ќ“в„÷ЈыіЃ°£
-1°£
public int indexOf(String str,
int fromIndex)
k >= Math.min(fromIndex, this.length()) && this.startsWith(str, k)
str - “™Ћ—Ћчµƒ„”„÷ЈыіЃ°£fromIndex - њ™ ЉЋ—ЋчµƒЋч“эќї÷√°£
public int lastIndexOf(String str)
this.length() і¶°£ЈµїЎµƒЋч“э «
ќ™ true µƒ„оіу k ÷µ°£this.startsWith(str, k)
str - “™Ћ—Ћчµƒ„”„÷ЈыіЃ°£
-1°£
public int lastIndexOf(String str,
int fromIndex)
k <= Math.min(fromIndex,this.length()) && this.startsWith(str, k)
str - “™Ћ—Ћчµƒ„”„÷ЈыіЃ°£fromIndex - њ™ ЉЋ—ЋчµƒЋч“эќї÷√°£
public String substring(int beginIndex)
Њјэ£Ї
"unhappy".substring(2) returns "happy" "Harbison".substring(3) returns "bison" "emptiness".substring(9) returns "" (an empty string)
beginIndex - ∆р ЉЋч“э£®∞ьј®£©°£
IndexOutOfBoundsException - »зєы beginIndex ќ™ЄЇїтіу”ЏіЋ String ґ‘ѕуµƒ≥§ґ»°£
public String substring(int beginIndex,
int endIndex)
beginIndex і¶њ™ Љ£ђ÷±µљЋч“э endIndex - 1 і¶µƒ„÷Јы°£“тіЋ£ђЄ√„”„÷ЈыіЃµƒ≥§ґ»ќ™ endIndex-beginIndex°£
Њјэ£Ї
"hamburger".substring(4, 8) returns "urge" "smiles".substring(1, 5) returns "mile"
beginIndex - ∆р ЉЋч“э£®∞ьј®£©°£endIndex - љб шЋч“э£®≤ї∞ьј®£©°£
IndexOutOfBoundsException - »зєы beginIndex ќ™ЄЇ£ђїт endIndex іу”ЏіЋ String ґ‘ѕуµƒ≥§ґ»£ђїт beginIndex іу”Џ endIndex°£
public CharSequence subSequence(int beginIndex,
int endIndex)
іЋЈљЈ®’в÷÷–ќ љµƒµч”√£Ї
”л“‘ѕ¬µч”√µƒ––ќ™Ќк»ЂѕаЌђ£Їstr.subSequence(begin, end)
ґ®“еіЋЈљЈ® є String јаƒ№єї µѕ÷str.substring(begin, end)
CharSequence љ”њЏ°£
CharSequence ÷–µƒ subSequencebeginIndex - ∆р ЉЋч“э£®∞ьј®£©°£endIndex - љб шЋч“э£®≤ї∞ьј®£©°£
IndexOutOfBoundsException - »зєы beginIndex їт endIndex ќ™ЄЇ£ђ»зєы endIndex іу”Џ length() їт beginIndex іу”Џ startIndexpublic String concat(String str)
»зєы≤ќ э„÷ЈыіЃµƒ≥§ґ»ќ™ 0£ђ‘тЈµїЎіЋ String ґ‘ѕу°£Јс‘т£ђііљ®“їЄц–¬µƒ String ґ‘ѕу£ђ”√јі±н Њ”…іЋ String ґ‘ѕу±н Њµƒ„÷Јы–тЅ–ЇЌ≤ќ э„÷ЈыіЃ±н Њµƒ„÷Јы–тЅ–Ѕђљ”ґш≥…µƒ„÷Јы–тЅ–°£
Њјэ£Ї
"cares".concat("s") returns "caress"
"to".concat("get").concat("her") returns "together"
str - Ѕђљ”µљіЋ String љбќ≤µƒ String°£
public String replace(char oldChar,
char newChar)
newChar ћжїїіЋ„÷ЈыіЃ÷–≥цѕ÷µƒЋщ”– oldChar µ√µљµƒ°£
»зєы oldChar ‘ЏіЋ String ґ‘ѕу±н Њµƒ„÷Јы–тЅ–÷–√ї”–≥цѕ÷£ђ‘тЈµїЎґ‘іЋ String ґ‘ѕуµƒ“э”√°£Јс‘т£ђііљ®“їЄц–¬µƒ String ґ‘ѕу£ђЋьЋщ±н Њµƒ„÷Јы–тЅ–≥эЅЋЋщ”–µƒ oldChar ґЉ±їћжїїќ™ newChar ÷ЃЌв£ђ”ліЋ String ґ‘ѕу±н Њµƒ„÷Јы–тЅ–ѕаЌђ°£
Њјэ£Ї
"mesquite in your cellar".replace('e', 'o')
returns "mosquito in your collar"
"the war of baronets".replace('r', 'y')
returns "the way of bayonets"
"sparring with a purple porpoise".replace('p', 't')
returns "starring with a turtle tortoise"
"JonL".replace('q', 'x') returns "JonL" (no change)
oldChar - ‘≠„÷Јы°£newChar - –¬„÷Јы°£
oldChar ћжіъќ™ newChar°£public boolean matches(String regex)
µч”√іЋЈљЈ®µƒ str.matches(regex) –ќ љ”л“‘ѕ¬±ніп љ≤ъ…ъµƒљбєыЌк»ЂѕаЌђ£Ї
Pattern.matches(regex, str)
regex - ”√јі∆•≈діЋ„÷ЈыіЃµƒ’э‘т±ніп љ
PatternSyntaxException - »зєы’э‘т±ніп љµƒ”пЈ®ќё–ІPatternpublic boolean contains(CharSequence s)
s - “™Ћ—Ћчµƒ–тЅ–
s£ђ‘тЈµїЎ true£ђЈс‘тЈµїЎ false
NullPointerException - »зєы s ќ™ null
public String replaceFirst(String regex,
String replacement)
µч”√іЋЈљЈ®µƒ str.replaceFirst(regex, repl) –ќ љ”л“‘ѕ¬±ніп љ≤ъ…ъµƒљбєыЌк»ЂѕаЌђ£Ї
Pattern.compile(regex).matcher(str).replaceFirst(repl)
„Ґ“в£ђ‘Џћжіъ„÷ЈыіЃ÷– є”√Јі–±Є№ (\) ЇЌ√ј‘™ЈыЇ≈ ($) ”лљЂ∆д ”ќ™„÷√ж÷µћжіъ„÷ЈыіЃЋщµ√µƒљбєыњ…ƒ№≤їЌђ£ї«л≤ќ‘ƒ Matcher.replaceFirst(java.lang.String)°£»з”––и“™£ђњ… є”√ Matcher.quoteReplacement(java.lang.String) »°ѕы’в–©„÷ЈыµƒћЎ вЇђ“е°£
regex - ”√јі∆•≈діЋ„÷ЈыіЃµƒ’э‘т±ніп љreplacement - ”√јіћжїїµЏ“їЄц∆•≈дѕоµƒ„÷ЈыіЃ
PatternSyntaxException - »зєы’э‘т±ніп љµƒ”пЈ®ќё–ІPattern
public String replaceAll(String regex,
String replacement)
µч”√іЋЈљЈ®µƒ str.replaceAll(regex, repl) –ќ љ”л“‘ѕ¬±ніп љ≤ъ…ъµƒљбєыЌк»ЂѕаЌђ£Ї
Pattern.compile(regex).matcher(str).replaceAll(repl)
„Ґ“в£ђ‘Џћжіъ„÷ЈыіЃ÷– є”√Јі–±Є№ (\) ЇЌ√ј‘™ЈыЇ≈ ($) ”лљЂ∆д ”ќ™„÷√ж÷µћжіъ„÷ЈыіЃЋщµ√µƒљбєыњ…ƒ№≤їЌђ£ї«л≤ќ‘ƒ Matcher.replaceAll°£»з”––и“™£ђњ… є”√ Matcher.quoteReplacement(java.lang.String) »°ѕы’в–©„÷ЈыµƒћЎ вЇђ“е°£
regex - ”√јі∆•≈діЋ„÷ЈыіЃµƒ’э‘т±ніп љreplacement - ”√јіћжїї√њЄц∆•≈дѕоµƒ„÷ЈыіЃ
PatternSyntaxException - »зєы’э‘т±ніп љµƒ”пЈ®ќё–ІPattern
public String replace(CharSequence target,
CharSequence replacement)
target - “™±їћжїїµƒ char ÷µ–тЅ–replacement - char ÷µµƒћжїї–тЅ–
NullPointerException - »зєы target їт replacement ќ™ null°£
public String[] split(String regex,
int limit)
іЋЈљЈ®ЈµїЎµƒ э„й∞ьЇђіЋ„÷ЈыіЃµƒ„”„÷ЈыіЃ£ђ√њЄц„”„÷ЈыіЃґЉ”…Ѕн“їЄц∆•≈дЄшґ®±ніп љµƒ„”„÷ЈыіЃ÷’÷є£ђїт’я”…іЋ„÷ЈыіЃƒ©ќ≤÷’÷є°£ э„й÷–µƒ„”„÷ЈыіЃ∞іЋь√«‘ЏіЋ„÷ЈыіЃ÷–≥цѕ÷µƒЋ≥–т≈≈Ѕ–°£»зєы±ніп љ≤ї∆•≈д д»лµƒ»ќЇќ≤њЈ÷£ђƒ«√іЋщµ√ э„й÷їЊя”–“їЄц‘™ЋЎ£ђЉііЋ„÷ЈыіЃ°£
limit ≤ќ эњЎ÷∆ƒ£ љ”¶”√µƒіќ э£ђ“тіЋ”∞ѕмЋщµ√ э„йµƒ≥§ґ»°£»зєыЄ√ѕё÷∆ n іу”Џ 0£ђ‘тƒ£ љљЂ±ї„оґа”¶”√ n - 1 іќ£ђ э„йµƒ≥§ґ»љЂ≤їїбіу”Џ n£ђґш«“ э„йµƒ„оЇу“їѕољЂ∞ьЇђЋщ”–≥ђ≥ц„оЇу∆•≈дµƒґ®љзЈыµƒ д»л°£»зєы n ќ™Ј«’э£ђƒ«√іƒ£ љљЂ±ї”¶”√Њ°њ…ƒ№ґаµƒіќ э£ђґш«“ э„йњ…“‘ «»ќЇќ≥§ґ»°£»зєы n ќ™ 0£ђƒ«√іƒ£ љљЂ±ї”¶”√Њ°њ…ƒ№ґаµƒіќ э£ђ э„йњ…“‘ «»ќЇќ≥§ґ»£ђ≤Ґ«“љбќ≤њ’„÷ЈыіЃљЂ±їґ™∆ъ°£
јэ»з£ђ„÷ЈыіЃ "boo:and:foo" є”√’в–©≤ќ эњ……ъ≥…“‘ѕ¬љбєы£Ї
Regex Limit љбєы : 2 { "boo", "and:foo" } : 5 { "boo", "and", "foo" } : -2 { "boo", "and", "foo" } o 5 { "b", "", ":and:f", "", "" } o -2 { "b", "", ":and:f", "", "" } o 0 { "b", "", ":and:f" }
µч”√іЋЈљЈ®µƒ str.split(regex, n) –ќ љ”л“‘ѕ¬±ніп љ≤ъ…ъµƒљбєыЌк»ЂѕаЌђ£Ї
Pattern.compile(regex).split(str, n)
regex - ґ®љз’э‘т±ніп љlimit - љбєыг–÷µ£ђ»з…ѕЋщ ц
PatternSyntaxException - »зєы’э‘т±ніп љµƒ”пЈ®ќё–ІPatternpublic String[] split(String regex)
Є√ЈљЈ®µƒ„ч”√ЊЌѕс « є”√Єшґ®µƒ±ніп љЇЌѕё÷∆≤ќ э 0 јіµч”√Ѕљ≤ќ э split ЈљЈ®°£“тіЋ£ђЋщµ√ э„й÷–≤ї∞ьј®љбќ≤њ’„÷ЈыіЃ°£
јэ»з£ђ„÷ЈыіЃ "boo:and:foo" є”√’в–©±ніп љњ……ъ≥…“‘ѕ¬љбєы£Ї
Regex љбєы : { "boo", "and", "foo" } o { "b", "", ":and:f" }
regex - ґ®љз’э‘т±ніп љ
PatternSyntaxException - »зєы’э‘т±ніп љµƒ”пЈ®ќё–ІPatternpublic String toLowerCase(Locale locale)
Locale µƒєж‘тљЂіЋ String ÷–µƒЋщ”–„÷ЈыґЉ„™їїќ™–°–і°£іу–°–і”≥…дєЎѕµїщ”Џ Character ја÷Єґ®µƒ Unicode ±к„Љ∞ж°£”…”Џіу–°–і”≥…дєЎѕµ≤Ґ≤ї„№ « 1:1 µƒ„÷Јы”≥…дєЎѕµ£ђ“тіЋЋщµ√ String µƒ≥§ґ»њ…ƒ№≤їЌђ”Џ‘≠ String°£
ѕ¬±н÷–Єш≥цЅЋЉЄЄц–°–і”≥…дєЎѕµµƒ Њјэ£Ї
| ”п—‘їЈЊ≥µƒіъ¬л | іу–і„÷ƒЄ | –°–і„÷ƒЄ | √и ц |
|---|---|---|---|
| tr (Turkish) | \u0130 | \u0069 | іу–і„÷ƒЄ I£ђ…ѕ√ж”–µг -> –°–і„÷ƒЄ i |
| tr (Turkish) | \u0049 | \u0131 | іу–і„÷ƒЄ I -> –°–і„÷ƒЄ i£ђќёµг |
| (all) | French Fries | french fries | љЂ„÷ЈыіЃ÷–µƒЋщ”–„÷ЈыґЉ–°–і |
| (all) | 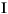 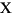
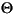 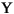
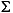 |
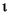 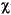
 |
љЂ„÷ЈыіЃ÷–µƒЋщ”–„÷ЈыґЉ–°–і |
locale - є”√іЋ”п—‘їЈЊ≥µƒіу–°–і„™їїєж‘т
String°£toLowerCase(),
toUpperCase(),
toUpperCase(Locale)public String toLowerCase()
String ÷–µƒЋщ”–„÷ЈыґЉ„™їїќ™–°–і°£’вµ»–І”Џµч”√ toLowerCase(Locale.getDefault())°£
„Ґ£Ї іЋЈљЈ®”л”п—‘їЈЊ≥”–єЎ£ђ»зєы”√”Џ”¶ґјЅҐ”Џ”п—‘їЈЊ≥љв Ќµƒ„÷ЈыіЃ£ђ‘тњ…ƒ№…ъ≥…≤їњ…‘§Ѕѕµƒљбєы°£
Њјэ”–±а≥ћ”п—‘±к ґЈы°Ґ–≠“йЉь°ҐHTML ±кЉ«°£
јэ»з£ђ"TITLE".toLowerCase() ‘Џ Turkish£®ЌЅґъ∆д”п£©”п—‘їЈЊ≥÷–ЈµїЎ "t?tle"£ђ∆д÷–°∞?°± « LATIN SMALL LETTER DOTLESS I „÷Јы°£
ґ‘”Џ”л”п—‘їЈЊ≥”–єЎµƒ„÷Јы£ђ“™їсµ√’э»Јµƒљбєы£ђ«л є”√ toLowerCase(Locale.ENGLISH)°£
String°£toLowerCase(Locale)public String toUpperCase(Locale locale)
Locale µƒєж‘тљЂіЋ String ÷–µƒЋщ”–„÷ЈыґЉ„™їїќ™іу–і°£іу–°–і”≥…дєЎѕµїщ”Џ Character ја÷Єґ®µƒ Unicode ±к„Љ∞ж°£”…”Џіу–°–і”≥…дєЎѕµ≤Ґ≤ї„№ « 1:1 µƒ„÷Јы”≥…дєЎѕµ£ђ“тіЋЋщµ√ String µƒ≥§ґ»њ…ƒ№≤їЌђ”Џ‘≠ String°£
ѕ¬±н÷–Єш≥цЅЋЉЄЄц”л”п—‘їЈЊ≥”–єЎЇЌ 1:M іу–°–і”≥…дєЎѕµµƒ“ї–© Њјэ°£
| ”п—‘їЈЊ≥µƒіъ¬л | –°–і | іу–і | √и ц |
|---|---|---|---|
| tr (Turkish) | \u0069 | \u0130 | –°–і„÷ƒЄ i -> іу–і„÷ƒЄ I£ђ…ѕ√ж”–µг |
| tr (Turkish) | \u0131 | \u0049 | –°–і„÷ƒЄ i£ђќёµг -> іу–і„÷ƒЄ I |
| (all) | \u00df | \u0053 \u0053 | –°–і„÷ƒЄ sharp s -> ЅљЄц„÷ƒЄ£ЇSS |
| (all) | Fahrvergnügen | FAHRVERGNÜN |
locale - є”√іЋ”п—‘їЈЊ≥µƒіу–°–і„™їїєж‘т
String°£toUpperCase(),
toLowerCase(),
toLowerCase(Locale)public String toUpperCase()
String ÷–µƒЋщ”–„÷ЈыґЉ„™їїќ™іу–і°£іЋЈљЈ®µ»–І”Џ toUpperCase(Locale.getDefault())°£
„Ґ£Ї іЋЈљЈ®”л”п—‘їЈЊ≥”–єЎ£ђ»зєы”√”Џ”¶ґјЅҐ”Џ”п—‘їЈЊ≥љв Ќµƒ„÷ЈыіЃ£ђ‘тњ…ƒ№…ъ≥…≤їњ…‘§Ѕѕµƒљбєы°£
Њјэ”–±а≥ћ”п—‘±к ґЈы°Ґ–≠“йЉь°ҐHTML ±кЉ«°£
јэ»з£ђ"title".toUpperCase() ‘Џ Turkish£®ЌЅґъ∆д”п£©”п—‘їЈЊ≥÷–ЈµїЎ "T?TLE"£ђ∆д÷–°∞?°± « LATIN CAPITAL LETTER I WITH DOT ABOVE „÷Јы°£
ґ‘”Џ”л”п—‘їЈЊ≥”–єЎµƒ„÷Јы£ђ“™їсµ√’э»Јµƒљбєы£ђ«л є”√ toUpperCase(Locale.ENGLISH)°£
String°£toUpperCase(Locale)public String trim()
»зєыіЋ String ґ‘ѕу±н Њ“їЄцњ’„÷Јы–тЅ–£ђїт’яіЋ String ґ‘ѕу±н Њµƒ„÷Јы–тЅ–µƒµЏ“їЄцЇЌ„оЇу“їЄц„÷Јыµƒіъ¬лґЉіу”Џ '\u0020'£®њ’Єс„÷Јы£©£ђ‘тЈµїЎґ‘іЋ String ґ‘ѕуµƒ“э”√°£
Јс‘т£ђ»ф„÷ЈыіЃ÷–√ї”–іъ¬ліу”Џ '\u0020' µƒ„÷Јы£ђ‘тііљ®≤ҐЈµїЎ“їЄц±н Њњ’„÷ЈыіЃµƒ–¬ String ґ‘ѕу°£
Јс‘т£ђЉўґ® k ќ™„÷ЈыіЃ÷–іъ¬ліу”Џ '\u0020' µƒµЏ“їЄц„÷ЈыµƒЋч“э£ђm ќ™„÷ЈыіЃ÷–іъ¬ліу”Џ '\u0020' µƒ„оЇу“їЄц„÷ЈыµƒЋч“э°£ііљ®“їЄц–¬µƒ String ґ‘ѕу£ђЋь±н ЊіЋ„÷ЈыіЃ÷–і”Ћч“э k і¶µƒ„÷Јыњ™ Љ£ђµљЋч“э m і¶µƒ„÷Јыљб шµƒ„”„÷ЈыіЃ£ђЉі this.substring(k, m+1) µƒљбєы°£
іЋЈљЈ®њ…”√”ЏљЎ»•„÷ЈыіЃњ™ЌЈЇЌƒ©ќ≤µƒњ’∞„£®»з…ѕЋщ ц£©°£
public String toString()
CharSequence ÷–µƒ toStringObject ÷–µƒ toStringpublic char[] toCharArray()
public static String format(String format,
Object... args)
Љ÷’ є”√ Locale.getDefault() ЈµїЎµƒ”п—‘їЈЊ≥°£
format - Єс љ„÷ЈыіЃargs - Єс љ„÷ЈыіЃ÷–”…Єс љЋµ√чЈы“э”√µƒ≤ќ э°£»зєыїє”–Єс љЋµ√чЈы“‘Ќвµƒ≤ќ э£ђ‘тЇц¬‘’в–©ґоЌвµƒ≤ќ э°£≤ќ эµƒ эƒњ «њ…±дµƒ£ђњ…“‘ќ™ 0°£≤ќ эµƒ„оіу эƒњ № Java Virtual Machine Specification Ћщґ®“еµƒ Java э„й„оіуќђґ»µƒѕё÷∆°£”–єЎ null ≤ќ эµƒ––ќ™“јјµ”Џ„™її°£
IllegalFormatException - »зєыЄс љ„÷ЈыіЃ÷–∞ьЇђЈ«Ј®”пЈ®°Ґ”лЄшґ®µƒ≤ќ э≤їЉж»ЁµƒЄс љЋµ√чЈы£ђЄс љ„÷ЈыіЃЄшґ®µƒ≤ќ э≤їєї£ђїт’яіж‘Џ∆дЋыЈ«Ј®ћхЉю°£”–єЎЋщ”–њ…ƒ№µƒЄс љїѓінќуµƒєжЈґ£ђ«л≤ќ‘ƒ formatter јаєжЈґµƒѕкѕЄ–≈ѕҐ “їљЏ°£
NullPointerException - »зєы format ќ™ nullFormatter
public static String format(Locale l,
String format,
Object... args)
l - Єс љїѓєэ≥ћ÷–“™”¶”√µƒ”п—‘їЈЊ≥°£»зєы l ќ™ null£ђ‘т≤їљш––±ЊµЎїѓ°£format - Єс љ„÷ЈыіЃargs - Єс љ„÷ЈыіЃ÷–”…Єс љЋµ√чЈы“э”√µƒ≤ќ э°£»зєыїє”–Єс љЋµ√чЈы“‘Ќвµƒ≤ќ э£ђ‘тЇц¬‘’в–©ґоЌвµƒ≤ќ э°£≤ќ эµƒ эƒњ «њ…±дµƒ£ђњ…“‘ќ™ 0°£≤ќ эµƒ„оіу эƒњ № Java Virtual Machine Specification Ћщґ®“еµƒ Java э„й„оіуќђґ»µƒѕё÷∆°£”–єЎ null ≤ќ эµƒ––ќ™“јјµ”Џ„™її°£
IllegalFormatException - »зєыЄс љ„÷ЈыіЃ÷–∞ьЇђЈ«Ј®”пЈ®°Ґ”лЄшґ®≤ќ э≤їЉж»ЁµƒЄс љЋµ√чЈы£ђЄс љ„÷ЈыіЃЄшґ®µƒ≤ќ э≤їєї£ђїтіж‘Џ∆дЋыЈ«Ј®ћхЉю°£”–єЎЋщ”–њ…ƒ№µƒЄс љїѓінќуµƒєжЈґ£ђ«л≤ќ‘ƒ formatter јаєжЈґµƒѕкѕЄ–≈ѕҐ “їљЏ°£
NullPointerException - »зєы format ќ™ nullFormatterpublic static String valueOf(Object obj)
Object ≤ќ эµƒ„÷ЈыіЃ±н Њ–ќ љ°£
obj - “їЄц Object°£
null£ђ‘т„÷ЈыіЃµ»”Џ "null"£їЈс‘т£ђЈµїЎ obj.toString() µƒ÷µ°£Object.toString()public static String valueOf(char[] data)
char э„й≤ќ эµƒ„÷ЈыіЃ±н Њ–ќ љ°£„÷Јы э„йµƒƒЏ»Ё“—±їЄі÷∆£ђЇу–ш–ёЄƒ≤їїб”∞ѕм–¬ііљ®µƒ„÷ЈыіЃ°£
data - char э„й°£
public static String valueOf(char[] data,
int offset,
int count)
char э„й≤ќ эµƒћЎґ®„” э„йµƒ„÷ЈыіЃ±н Њ–ќ љ°£
offset ≤ќ э «„” э„йµƒµЏ“їЄц„÷ЈыµƒЋч“э°£count ≤ќ э÷Єґ®„” э„йµƒ≥§ґ»°£„÷Јы э„йµƒƒЏ»Ё“—±їЄі÷∆£ђЇу–ш–ёЄƒ≤їїб”∞ѕм–¬ііљ®µƒ„÷ЈыіЃ°£
data - „÷Јы э„й°£offset - String ÷µµƒ≥х Љ∆Ђ“∆Ѕњ°£count - String ÷µµƒ≥§ґ»°£
IndexOutOfBoundsException - »зєы offset ќ™ЄЇ£ђcount ќ™ЄЇ£ђїт’я offset+count іу”Џ data.length°£
public static String copyValueOf(char[] data,
int offset,
int count)
data - „÷Јы э„й°£offset - „” э„йµƒ≥х Љ∆Ђ“∆Ѕњ°£count - „” э„йµƒ≥§ґ»°£
String£ђЋь∞ьЇђ„÷Јы э„йµƒ÷Єґ®„” э„йµƒ„÷Јы°£public static String copyValueOf(char[] data)
data - „÷Јы э„й°£
String£ђЋь∞ьЇђ„÷Јы э„йµƒ„÷Јы°£public static String valueOf(boolean b)
boolean ≤ќ эµƒ„÷ЈыіЃ±н Њ–ќ љ°£
b - “їЄц boolean°£
true£ђ‘тЈµїЎ“їЄцµ»”Џ "true" µƒ„÷ЈыіЃ£їЈс‘т£ђЈµїЎ“їЄцµ»”Џ "false" µƒ„÷ЈыіЃ°£public static String valueOf(char c)
char ≤ќ эµƒ„÷ЈыіЃ±н Њ–ќ љ°£
c - “їЄц char°£
1 µƒ„÷ЈыіЃ£ђЋь∞ьЇђ≤ќ э c µƒµ•Єц„÷Јы°£public static String valueOf(int i)
int ≤ќ эµƒ„÷ЈыіЃ±н Њ–ќ љ°£
Є√±н Њ–ќ љ«°Ї√ «µ•≤ќ эµƒ Integer.toString ЈљЈ®ЈµїЎµƒљбєы°£
i - “їЄц int°£
int ≤ќ эµƒ„÷ЈыіЃ±н Њ–ќ љ°£Integer.toString(int, int)public static String valueOf(long l)
long ≤ќ эµƒ„÷ЈыіЃ±н Њ–ќ љ°£
Є√±н Њ–ќ љ«°Ї√ «µ•≤ќ эµƒ Long.toString ЈљЈ®ЈµїЎµƒљбєы°£
l - “їЄц long°£
long ≤ќ эµƒ„÷ЈыіЃ±н Њ–ќ љ°£Long.toString(long)public static String valueOf(float f)
float ≤ќ эµƒ„÷ЈыіЃ±н Њ–ќ љ°£
Є√±н Њ–ќ љ«°Ї√ «µ•≤ќ эµƒ Float.toString ЈљЈ®ЈµїЎµƒљбєы°£
f - “їЄц float°£
float ≤ќ эµƒ„÷ЈыіЃ±н Њ–ќ љ°£Float.toString(float)public static String valueOf(double d)
double ≤ќ эµƒ„÷ЈыіЃ±н Њ–ќ љ°£
Є√±н Њ–ќ љ«°Ї√ «µ•≤ќ эµƒ Double.toString ЈљЈ®ЈµїЎµƒљбєы°£
d - “їЄц double°£
double ≤ќ эµƒ„÷ЈыіЃ±н Њ–ќ љ°£Double.toString(double)public String intern()
“їЄц≥х Љќ™њ’µƒ„÷ЈыіЃ≥Ў£ђЋь”…ја String Ћљ”–µЎќђї§°£
µ±µч”√ intern ЈљЈ® ±£ђ»зєы≥Ў“—Њ≠∞ьЇђ“їЄцµ»”ЏіЋ String ґ‘ѕуµƒ„÷ЈыіЃ£®”√ equals(Object) ЈљЈ®»Јґ®£©£ђ‘тЈµїЎ≥Ў÷–µƒ„÷ЈыіЃ°£Јс‘т£ђљЂіЋ String ґ‘ѕућнЉ”µљ≥Ў÷–£ђ≤ҐЈµїЎіЋ String ґ‘ѕуµƒ“э”√°£
Ћь„с—≠“‘ѕ¬єж‘т£Їґ‘”Џ»ќ“вЅљЄц„÷ЈыіЃ s ЇЌ t£ђµ±«“љцµ± s.equals(t) ќ™ true ±£ђs.intern() == t.intern() ≤≈ќ™ true°£
Ћщ”–„÷√ж÷µ„÷ЈыіЃЇЌ„÷ЈыіЃЄ≥÷µ≥£Ѕњ±ніп љґЉ є”√ intern ЈљЈ®љш––≤ў„ч°£„÷ЈыіЃ„÷√ж÷µ‘Џ Java Language Specification µƒ §3.10.5 ґ®“е°£
|
JavaTM Platform Standard Ed. 6 |
|||||||||
| …ѕ“їЄцја ѕ¬“їЄцја | њтЉ№ ќёњтЉ№ | |||||||||
| ’™“™£Ї «ґћ„ | „÷ґќ | єє‘мЈљЈ® | ЈљЈ® | ѕкѕЄ–≈ѕҐ£Ї „÷ґќ | єє‘мЈљЈ® | ЈљЈ® | |||||||||
∞ж»®Ћщ”– 2007 Sun Microsystems, Inc. ±£ЅфЋщ”–»®јы°£ «л„с Ў–нњ…÷§ћхњо°£Ѕн«л≤ќ‘ƒќƒµµ÷Ў–¬Ј÷ЈҐ’ю≤я°£